论文不详细解读(一) |
您所在的位置:网站首页 › moco v1实战 › 论文不详细解读(一) |
论文不详细解读(一)
|
引言: 自监督发展时间线 论文名称: Momentum Contrast for Unsupervised Visual Representation Learning 开源地址:https://github.com/facebookresearch/moco 大佬详细解读:https://zhuanlan.zhihu.com/p/382763210 motivation原始的端到端自监督方法: 给定样本 x q x_q xq,数据增强得到正样本 x k x_k xk,batch内的其余样本作为负样本 原始样本 x q x_q xq输入到Encoder f q f_q fq中,正样本和负样本均输入到Encoder f k f_k fk中,通过Contrastive loss来更新2个Encoder f q f_q fq和 f k f_k fk的参数 Contrastive loss一般为InfoNCE: 毫无疑问,batch size 越大效果越好,但是受显存影响(2个encoder的全量数据都用于更新两个encoder的参数),batchsize不能设置过大,如何获得更多的负样本? MoCo v1之前的做法: 正样本的生成方式不变(数据增强),采用一个较大的memory bank 用来存储负样本,每次训练从中采样一批负样本出来 k s a m p l e k_{sample} ksample,loss只更新Encoder f q f_q fq 的参数,和几个采样的 k s a m p l e k_{sample} ksample值 。因为这时候没有了 Encoder f k f_k fk的反向传播,所以支持memory bank容量很大。 上述方法存在的弊端: Encoder f q f_q fq每个step都会更新,但是某一个 k s a m p l e i k_{sample}^i ksamplei可能很多个step才被采样到更新一次,而且一个epoch只会更新一次。这样最新的 query 采样得到的 key 可能是好多个step之前的编码器编码得到的 key,因此丧失了一致性。 MoCo的解决方法momentum (移动平均更新模型权重) 与queue (字典) 假设 Batch size 的大小是 N N N ,现在有个队列 Queue,这个队列的大小是 K ( K > N ) K(K>N) K(K>N),为了方便更新, K K K一般是 N N N的整数倍(代码里面 K = 65536 K=65536 K=65536)。 如上图所示,有俩网络,一个是 Encoder ,另一个是Momentum Encoder 。这两个模型的网络结构是一样的,初始参数也是一样的 (但是训练开始后两者参数将不再一样了)。 f q f_q fq与 f m k f_{mk} fmk是将输入信息映射到特征空间的网络。 样本 x x x经过两种数据增强分别得到样本 x q x_q xq和 x k x_k xk, x q x_q xq经过Encoder f q f_q fq得到特征 q q q(维度 N × C N×C N×C), x k x_k xk经过Encoder f m k f_{mk} fmk得到特征 k k k(维度 N × C N×C N×C), q q q和 k k k为两个正样本特征 其中k=k.detach(),不使用梯度更新 f m k f_{mk} fmk的参数 moco伪代码 f_k.params = f_q.params # 初始化 for x in loader: # 输入一个图像序列x,包含N张图,没有标签 x_q = aug(x) # 用于查询的图(数据增强得到) x_k = aug(x) # 模板图(数据增强得到),自监督就体现在这里,只有图x和x的数据增强才被归为一类 q = f_q.forward(x_q) # 提取查询特征,输出NxC k = f_k.forward(x_k) # 提取模板特征,输出NxC # 不使用梯度更新f_k的参数,这是因为文章假设用于提取模板的表示应该是稳定的,不应立即更新 k = k.detach() # 这里bmm是分批矩阵乘法 l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # 输出Nx1,也就是自己与自己的增强图的特征的匹配度 l_neg = mm(q.view(N,C), queue.view(C,K)) # 输出Nxk,自己与上一批次所有图的匹配度(全不匹配) logits = cat([l_pos, l_neg], dim=1) # 输出Nx(1+k) labels = zeros(N) # 正样本全在第0位 # NCE损失函数,就是为了保证自己与自己衍生的匹配度输出越大越好,否则越小越好 loss = CrossEntropyLoss(logits/t, labels) loss.backward() update(f_q.params) # f_q使用梯度立即更新 # 由于假设模板特征的表示方法是稳定的,因此它更新得更慢,这里使用动量法更新,相当于做了个滤波。 f_k.params = m*f_k.params+(1-m)*f_q.params enqueue(queue, k) # 为了生成反例,所以引入了队列 dequeue(queue)下图展示的是logits某一行的信息,这里的 K=2。 训练参数: 优化器:SGD,weight decay: 0.0001,momentum: 0.9。Batch size: 256初始学习率: 0.03,200 epochs,在第120和第160 epochs时分别乘以0.1,结束时是0.0003。附上一些思考: 🌱 Momentum Encoder输入的是正样本 x k x_k xk和负样本queue中的全量样本(区别于memory bank 采样输入负样本) 🌱 负样本队列queue的更新条件是什么? 队列存满会把最旧的样本batch替换成最新的batch,队列长度K不是样本总数量,而是远远小于总数量的(65535 vs 几百万),所以queue内存在和query正样本的概率比较小 🌱 数据增强的方式: Randomly resized image + random color jitteringRandom horizontal flipRandom grayscale conversion此外,作者还把 BN 替换成了 Shuffling BN,因为 BN 会欺骗 pretext task,轻易找到一种使得 loss 下降很快的方法。 🌱 对比端到端自监督的方法,MoCo的负样本数量为
K
K
K(queue长度),端到端负样本数量为
b
a
t
c
h
s
i
z
e
−
1
batchsize - 1
batchsize−1 🌱 为什么momentum encoder参数更新m=0时会训练失败而端到端自监督训练时却没有失败? 对于动量参数更新m的消融实验: 🌱 源码中一些比较巧妙的点: 1) queue实际存的是负样本的embedding,为了方便计算loss 所以用的是tensor形式,负样本进出队列实际使用一个索引 ptr 显示的样本替换位置 论文名称: Improved Baselines with Momentum Contrastive Learning 一句话概述:v2 将 SimCLR的两个提点的方法 (a. 使用预测头; b. 使用强大的数据增强策略Gaussian Deblur) 移植到了 MoCo v1上面 3. MoCo v3论文名称: An Empirical Study of Training Self-Supervised Vision Transformers 这篇论文的重点是将目前无监督学习最常用的对比学习应用在 ViT 上。作者给出的结论是:影响自监督ViT模型训练的关键是:instability,即训练的不稳定性。 而这种训练的不稳定性所造成的结果并不是训练过程无法收敛 (convergence),而是性能的轻微下降 (下降1%-3%的精度)。 MoCo v3框架 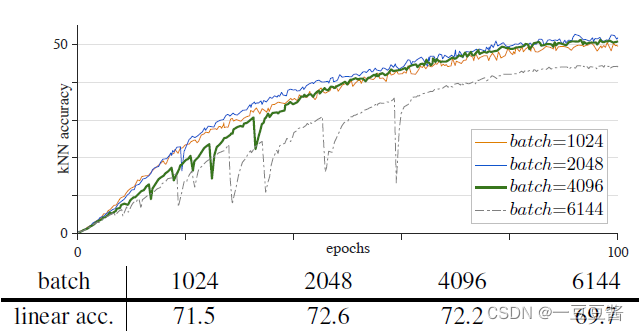 Learning rate 过大使得训练不稳定 (Batch size=4096,100个epoch)作者使用了4种不同的 Learning rate:0.5e-4, 1.0e-4, 1.5e-4 的结果。可以看到当Learning rate 较大时,曲线出现了 dip 现象 (稍稍落下又急速升起)。这种不稳定现象导致了精度出现下降。 Learning rate 过大使得训练不稳定 (Batch size=4096,100个epoch)作者使用了4种不同的 Learning rate:0.5e-4, 1.0e-4, 1.5e-4 的结果。可以看到当Learning rate 较大时,曲线出现了 dip 现象 (稍稍落下又急速升起)。这种不稳定现象导致了精度出现下降。  提升训练稳定性的方法:冻结第1层 (patch embedding层) 参数 上述实验表明 Batch size 或者 learning rate 的细微变化都有可能导致 Self-Supervised ViT 的训练不稳定。作者发现导致训练出现不稳定的这些 dip 跟梯度暴涨 (spike) 有关,如下图所示,第1层会先出现梯度暴涨的现象,结果几十次迭代后,会传到到最后1层。 提升训练稳定性的方法:冻结第1层 (patch embedding层) 参数 上述实验表明 Batch size 或者 learning rate 的细微变化都有可能导致 Self-Supervised ViT 的训练不稳定。作者发现导致训练出现不稳定的这些 dip 跟梯度暴涨 (spike) 有关,如下图所示,第1层会先出现梯度暴涨的现象,结果几十次迭代后,会传到到最后1层。 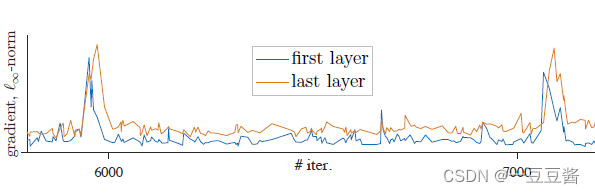 一旦第1层梯度暴涨,这个现象就会在几十次迭代之内传遍整个网络。所以说想解决训练出现不稳定的问题就不能让第1层出现梯度暴涨! 所以作者解决的办法是冻结第1层的参数,也就是patch embedding那层,随机初始化后,不再更新这一层的参数,然后发现好使。 一旦第1层梯度暴涨,这个现象就会在几十次迭代之内传遍整个网络。所以说想解决训练出现不稳定的问题就不能让第1层出现梯度暴涨! 所以作者解决的办法是冻结第1层的参数,也就是patch embedding那层,随机初始化后,不再更新这一层的参数,然后发现好使。 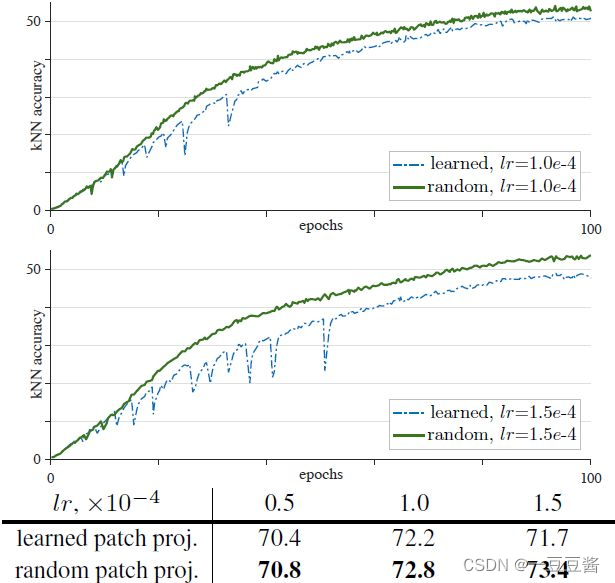 超参数细节 超参数细节 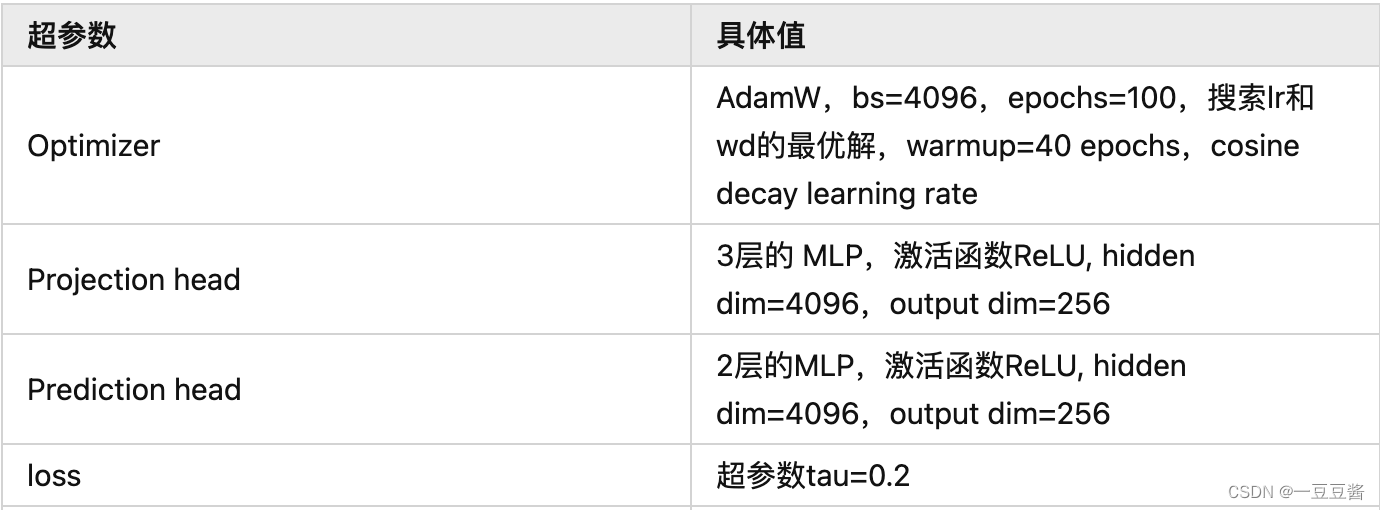
|
 图来自:https://zhuanlan.zhihu.com/p/381354026
图来自:https://zhuanlan.zhihu.com/p/381354026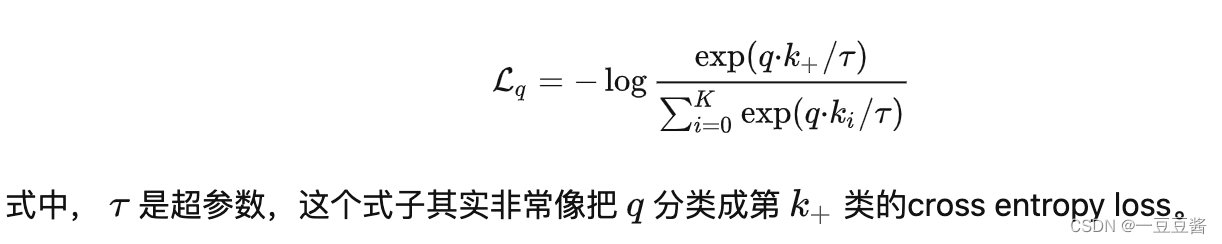 【插入一个参考资料:对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用】
【插入一个参考资料:对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用】


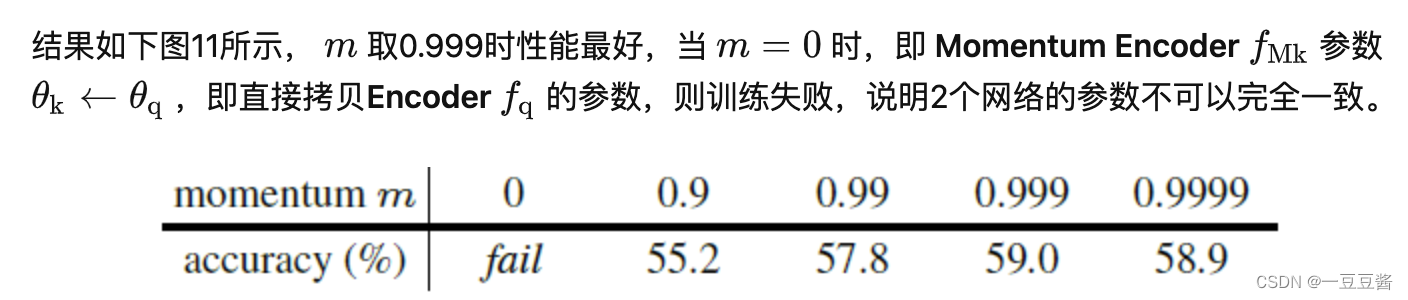 (仅个人理解)m=0说明两个encoder的参数完全一致,而moco在实现的时候其实queue中存的是embedding,仅复制参数相当于只更新了正样本
x
k
x_k
xk的特征,而queue中的负样本特征没有更新到,对应的还是很多个step之前的特征,还是有一致性的问题存在
(仅个人理解)m=0说明两个encoder的参数完全一致,而moco在实现的时候其实queue中存的是embedding,仅复制参数相当于只更新了正样本
x
k
x_k
xk的特征,而queue中的负样本特征没有更新到,对应的还是很多个step之前的特征,还是有一致性的问题存在 2)对于
x
k
x_k
xk使用了shuffle 与unshuffle
2)对于
x
k
x_k
xk使用了shuffle 与unshuffle 
【本文地址】